
How to Build a Local AI-Powered OCR App with Gemma-3 and Streamlit?
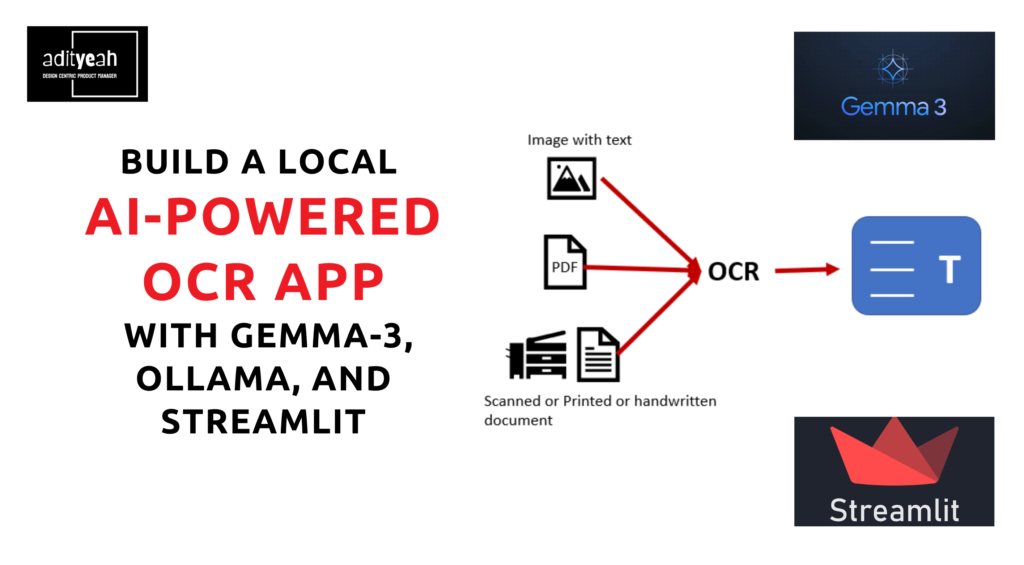
Optical Character Recognition (OCR) is an essential tool for extracting text from images, making it easier to digitize documents, analyze handwritten notes, and process structured information. With advancements in AI, OCR has become more accessible and efficient, allowing developers and product managers to integrate it into their workflows seamlessly.
In this guide, we’ll walk you through building your own locally running OCR app using Google’s Gemma-3 Vision model, Ollama, and Streamlit. This app allows users to upload an image and extract structured text in Markdown format, ensuring clarity and organization.
What is Ollama, Gemma-3, and Streamlit?
Before we dive into the setup, let’s understand the key components of our application:
Ollama: A lightweight tool that allows you to run large language models locally on your machine. It helps deploy models efficiently without requiring cloud-based services.
Gemma-3 Vision Model: A powerful multimodal AI model developed by Google that can process both images and text, making it ideal for OCR tasks.
Streamlit: A Python-based framework that makes it easy to create interactive web applications for machine learning models and data visualization.
With these three tools, we can build a fully functional OCR app that runs entirely on your local machine.
Step-by-Step Guide to Set Up and Run the OCR App
1. Install Ollama
To run Gemma-3 locally, we first need to install Ollama.
On Linux:
curl -fsSL https://ollama.com/install.sh | sh
On Mac:
brew install ollama
On Windows (using WSL 2):
wsl --install
curl -fsSL https://ollama.com/install.sh | sh
After installation, verify that Ollama is installed by running:
ollama --version
2. Download the Gemma-3 Vision Model
Once Ollama is set up, download and load the Gemma-3 Vision model:
ollama run gemma3:12b
This command ensures that the model is available on your local machine for inference.
3. Install Python and Required Dependencies
Ensure you have Python 3.11 or later installed. Then, install the necessary Python packages:
pip install streamlit ollama pillow
4. Create the Streamlit App
Now, let’s write the Python script that powers our OCR application. Save the following code as
app.py:
import streamlit as st
import ollama
from PIL import Image
import io
import base64
# Page configuration
st.set_page_config(
page_title="Gemma-3 OCR",
page_icon="🔎",
layout="wide",
initial_sidebar_state="expanded"
)
# Title and description in main area
st.markdown("""
# <img decoding="async" src="data:image/png;base64,{}" width="50" style="vertical-align: -12px;"> Gemma-3 OCR
""".format(base64.b64encode(open("./assets/gemma3.png", "rb").read()).decode()), unsafe_allow_html=True)
# Add clear button to top right
col1, col2 = st.columns([6,1])
with col2:
if st.button("Clear 🗑️"):
if 'ocr_result' in st.session_state:
del st.session_state['ocr_result']
st.rerun()
st.markdown('<p style="margin-top: -20px;">Extract structured text from images using Gemma-3 Vision!</p>', unsafe_allow_html=True)
st.markdown("---")
# Move upload controls to sidebar
with st.sidebar:
st.header("Upload Image")
uploaded_file = st.file_uploader("Choose an image...", type=['png', 'jpg', 'jpeg'])
if uploaded_file is not None:
# Display the uploaded image
image = Image.open(uploaded_file)
st.image(image, caption="Uploaded Image")
if st.button("Extract Text 🔍", type="primary"):
with st.spinner("Processing image..."):
try:
response = ollama.chat(
model='gemma3:12b',
messages=[{
'role': 'user',
'content': """Analyze the text in the provided image. Extract all readable content
and present it in a structured Markdown format that is clear, concise,
and well-organized. Ensure proper formatting (e.g., headings, lists, or
code blocks) as necessary to represent the content effectively.""",
'images': [uploaded_file.getvalue()]
}]
)
st.session_state['ocr_result'] = response.message.content
except Exception as e:
st.error(f"Error processing image: {str(e)}")
# Main content area for results
if 'ocr_result' in st.session_state:
st.markdown(st.session_state['ocr_result'])
else:
st.info("Upload an image and click 'Extract Text' to see the results here.")
# Footer
st.markdown("---")
st.markdown("Made with ❤️ using Gemma-3 Vision Model | [Adityeah](https://adityeah.in/)")
5. Run the Streamlit App
Once the script is ready, launch the Streamlit app by running:
streamlit run app.py
Your OCR app will be accessible in your browser, allowing you to upload an image and extract structured text.
Use Cases of OCR Across Domains
Education
Automated Exam Grading: Teachers can upload images of students’ answer sheets, and the model can compare student responses with predefined correct answers to automate grading and feedback generation.
Homework Evaluation: Students can submit handwritten homework, which the model can analyze for correctness and provide instant feedback.
Doubt Resolution: Students can upload handwritten queries, and the model can extract and structure the content for quick reference and resolution.
Digitizing Study Materials: OCR can convert handwritten notes, books, and lecture slides into digital formats for better accessibility.
Finance
Automated Invoice Processing: OCR extracts and processes financial data from invoices and receipts for accounting automation.
Check and Bank Statement Scanning: Quickly digitize paper checks and bank statements to track transactions more efficiently.
Fraud Detection: OCR can verify documents for discrepancies in financial reports and detect potential fraud.
Healthcare
Medical Record Digitization: Convert handwritten doctor notes and prescriptions into electronic health records (EHRs) for better accessibility.
Insurance Claims Processing: Extract data from claim forms and automate insurance approvals.
Patient Form Processing: Reduce paperwork by digitizing patient intake forms and medical histories.
Retail & Logistics
Barcode and Label Scanning: Automate inventory tracking by extracting data from labels and barcodes.
Automated Receipt Processing: Digitize and categorize receipts for expense tracking and reimbursement.
Order Management: OCR extracts shipping and order details from printed documents to streamline logistics operations.
With OCR technology becoming more powerful and accessible, businesses across industries can leverage it to automate workflows, enhance efficiency, and improve data accuracy.

About the Author
