
Finally, a Text-to-SQL Tool That Actually Works — Meet Vanna AI

In a world where data is the new oil, querying it shouldn’t feel like learning a new language.
And yet, that’s what most non-technical users face when trying to interact with databases.
Enter Vanna AI: a powerful, 100% open-source Retrieval-Augmented Generation (RAG) framework that converts natural language into accurate SQL queries—securely, scalably, and seamlessly.
With over 14,000 GitHub stars, Vanna has captured the attention of data teams, product managers, and developers for one simple reason:
It just works.
🚀 What is Vanna AI?
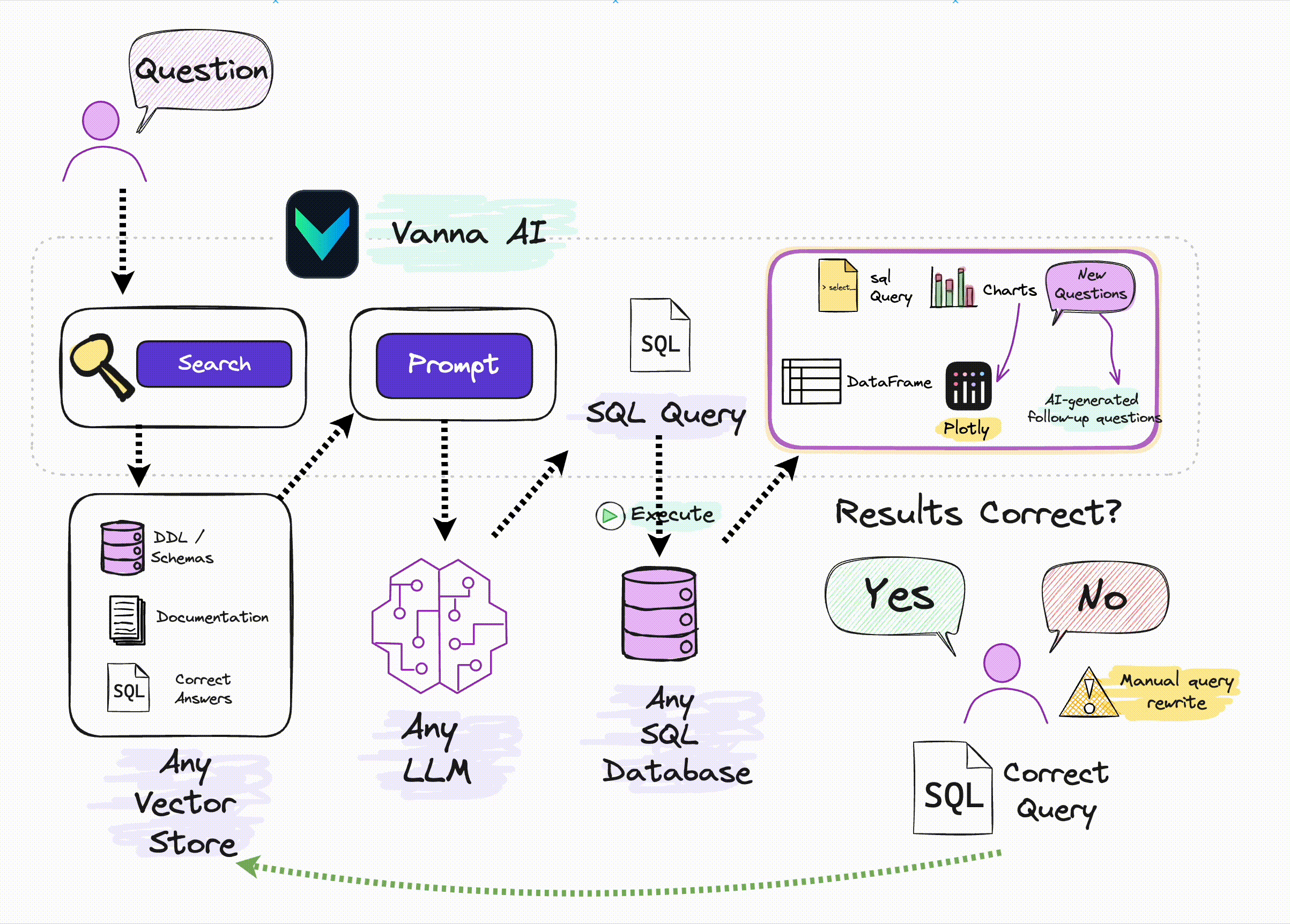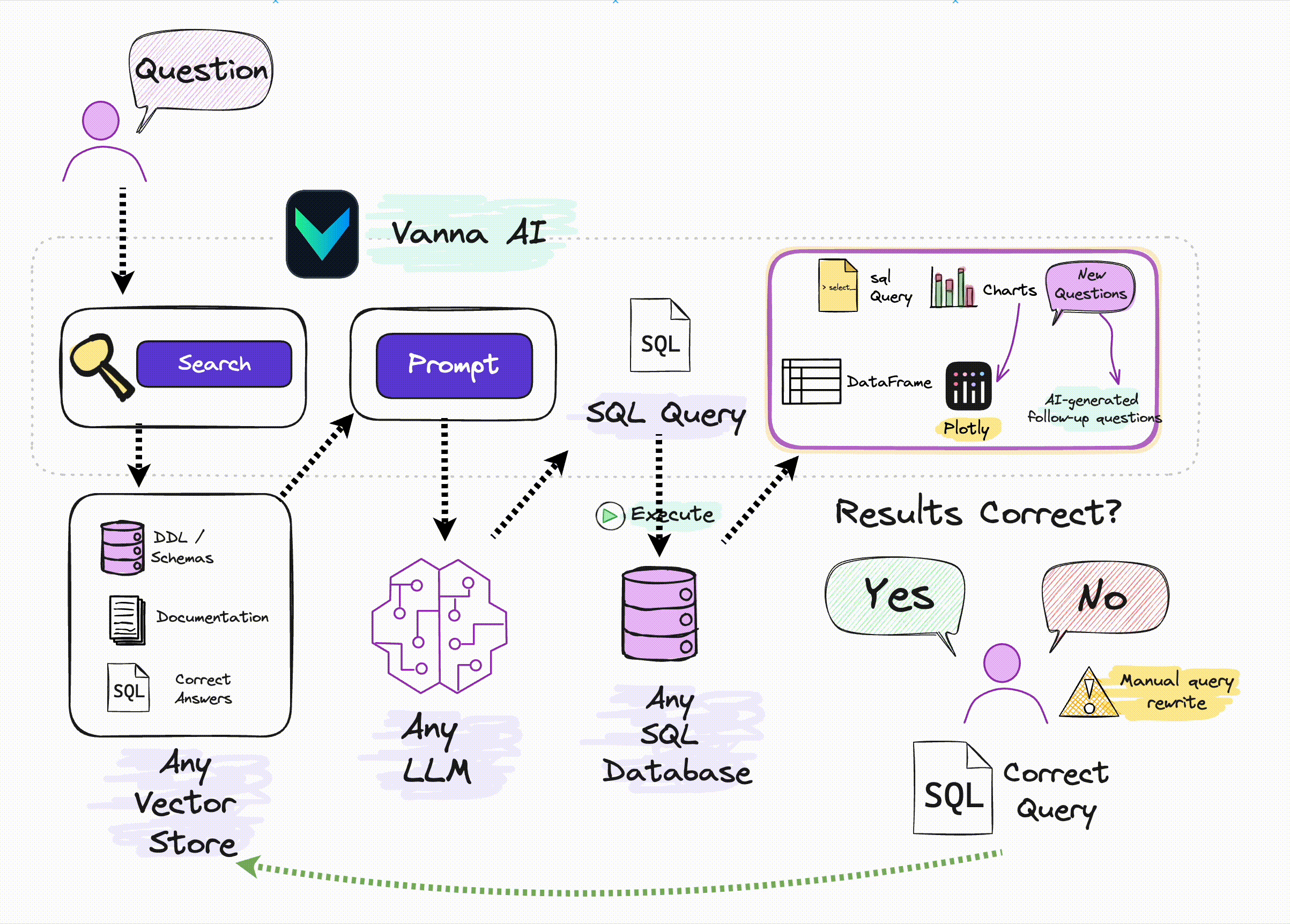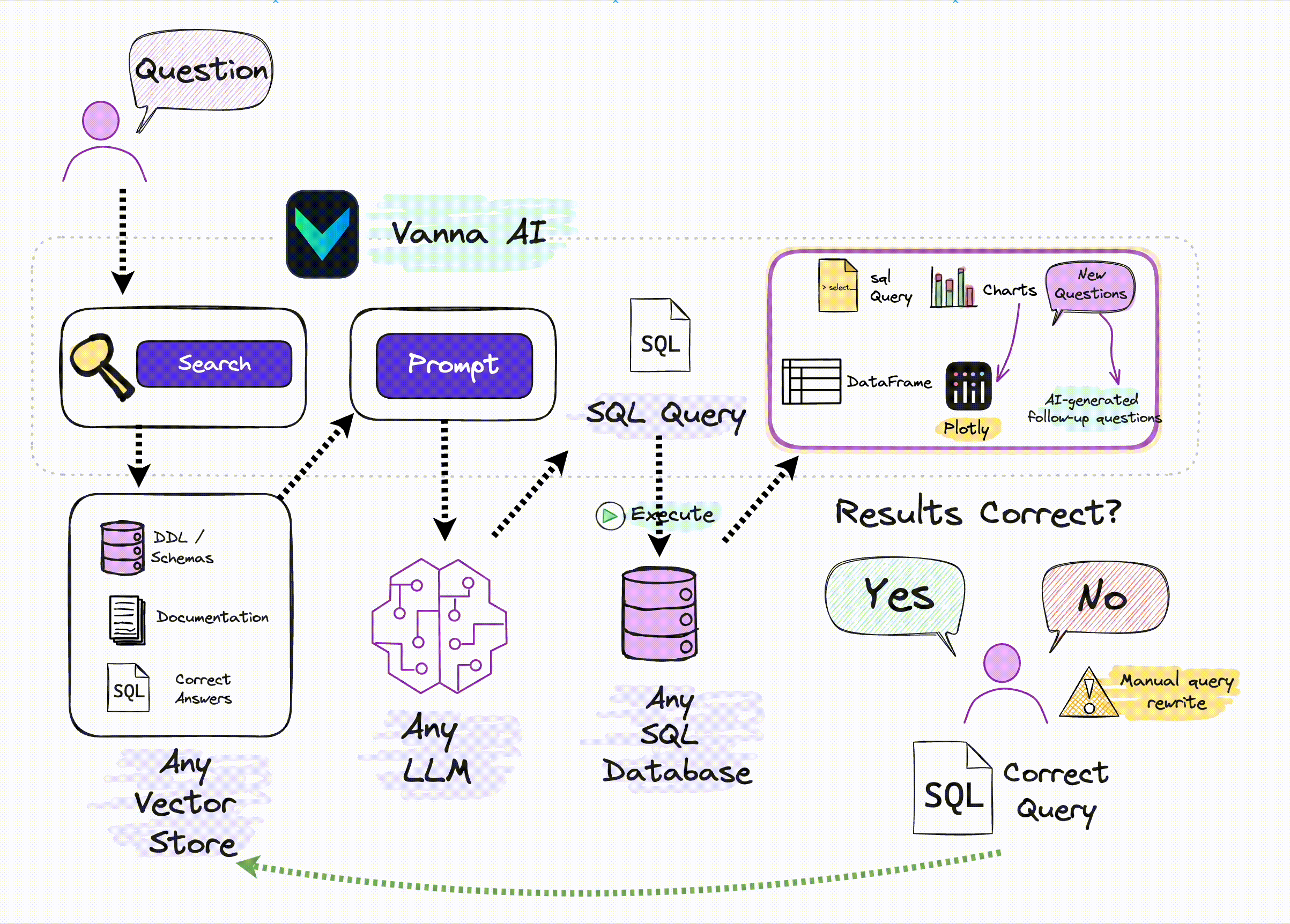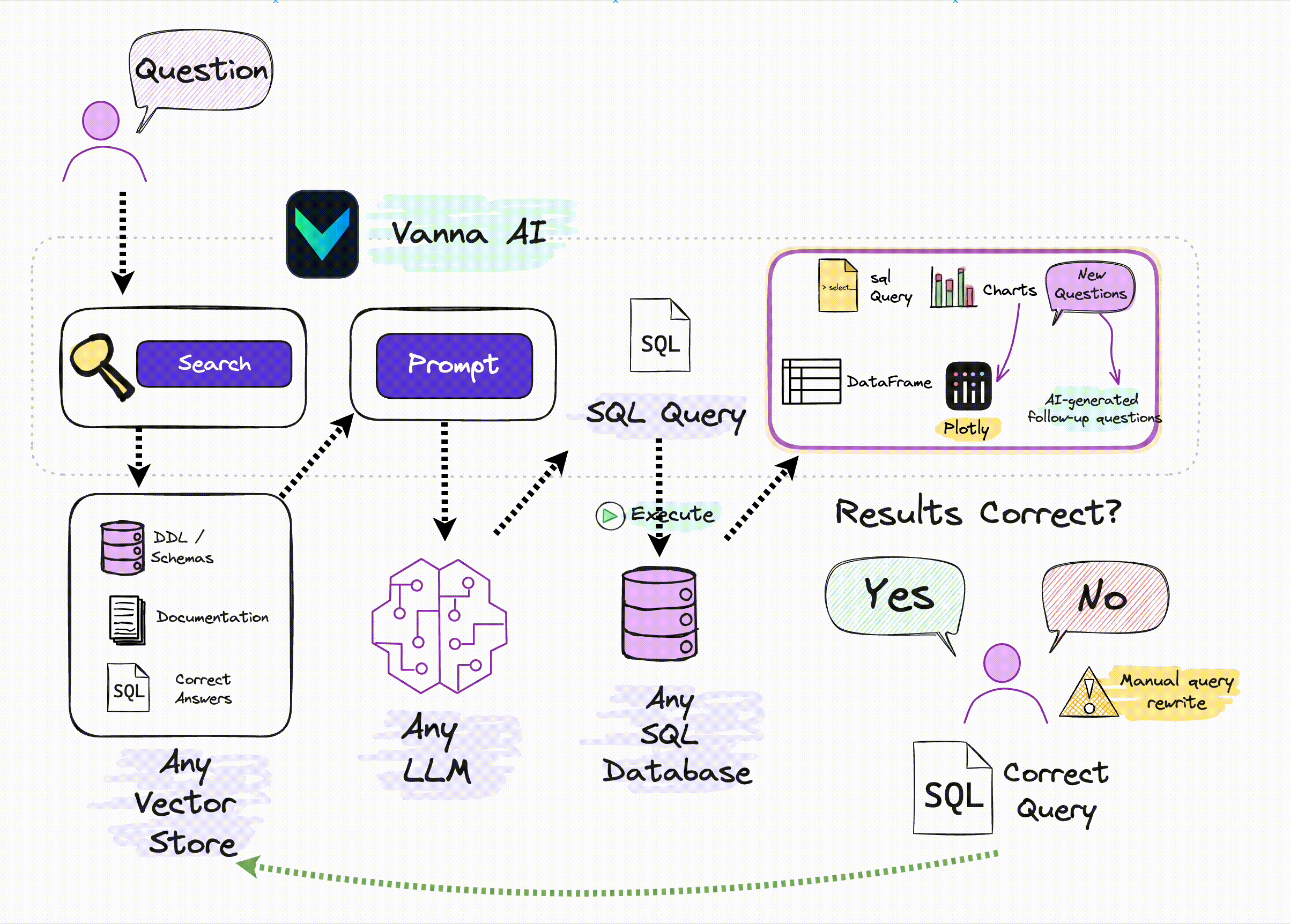
Vanna AI is an open-source Text-to-SQL engine built on RAG (Retrieval-Augmented Generation), specifically designed to handle complex, dynamic datasets like the ones used in modern enterprises.
At its core, Vanna makes databases talk back in plain English. Whether you’re working with Snowflake, Redshift, Postgres, or BigQuery, Vanna translates your questions into SQL queries that run directly on your data.
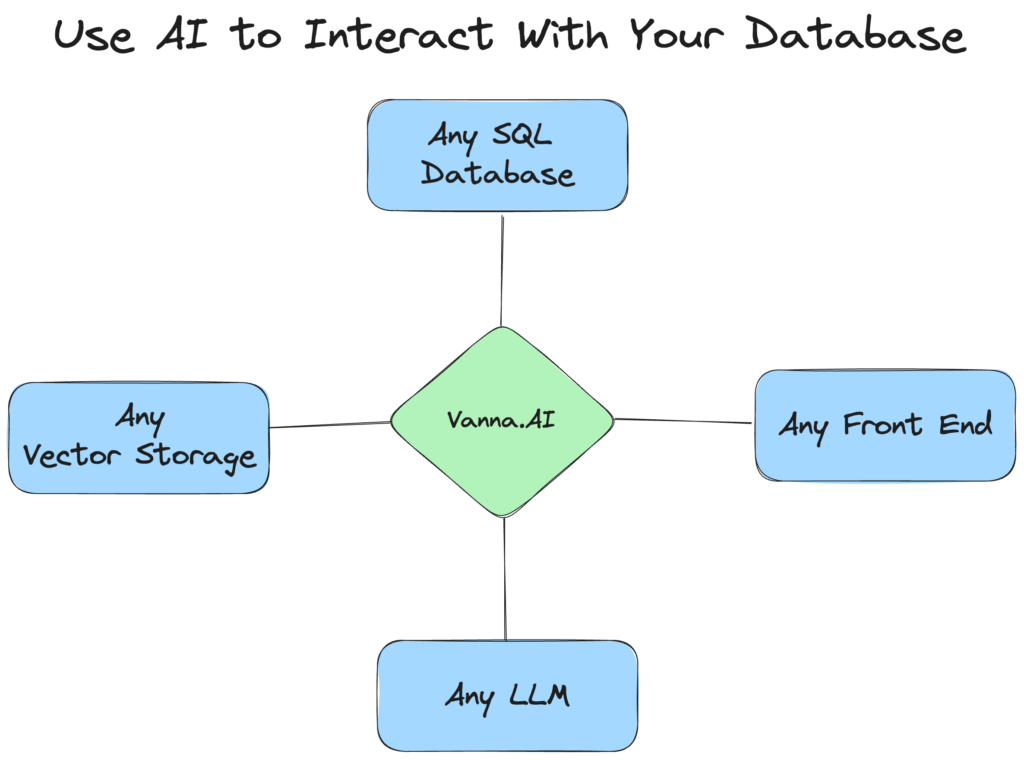
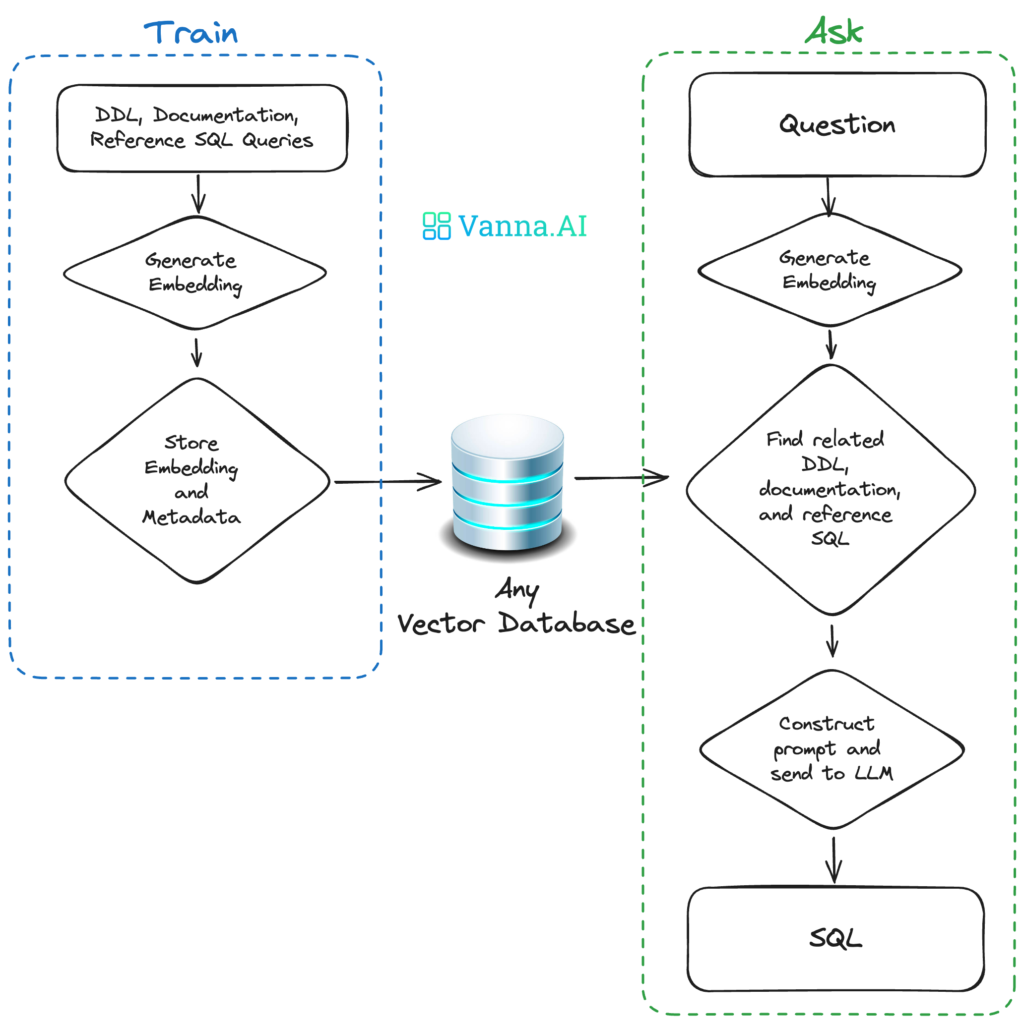
🧠 How Vanna Works in 2 Steps
Using Vanna is surprisingly simple:
1️⃣ Train a RAG model on your database schema, documentation, and query logs (it creates a knowledge base).
2️⃣ Ask your business question in plain English. Vanna generates SQL that can directly run on your DB—or be reviewed by analysts before execution.
And yes, it gets smarter with each question.
🔑 Key Features
| Feature | Description |
|---|---|
| 🎯 High Accuracy | Handles nested, complex SQL queries with better performance than most LLM-only tools. |
| 🧠 Self-Learning | Continuously improves by learning from past queries and feedback. |
| 🔒 Secure by Design | Your data stays within your environment—Vanna only needs metadata, not actual records. |
| 🌐 Database-Agnostic | Supports all major SQL databases: Postgres, Snowflake, Redshift, MySQL, SQL Server, and more. |
| 💻 Flexible Frontends | Integrate Vanna with Jupyter Notebooks, Slack bots, Streamlit apps, or even Flask APIs. |
⚙️ Under the Hood: Architecture Overview
Vanna combines the best of three layers:
LLMs (OpenAI, Anthropic, Gemini, etc.) – For interpreting natural language and generating human-like SQL.
Vector DBs (ChromaDB, FAISS, Qdrant, etc.) – To search and retrieve relevant metadata, schemas, or logs.
SQL Connectors – For seamless execution or validation on live databases.
The stack is modular—you choose which LLM, which vector store, and which database you want to plug in.
💡 Use Cases
Vanna isn’t just a technical marvel. It’s also practically useful:
📊 Business Intelligence: Non-technical users can query without writing SQL.
🔍 Exploratory Analysis: Analysts can speed up data discovery.
👨🏫 Education: Helps learners understand the SQL equivalent of business questions.
🛠 Internal Tools: Integrate into Slack, dashboards, or internal portals for real-time data Q&A.
🔧 Installation & Example
Want to try it? Just:
pip install vanna
Note: Depending on the LLM and vector store used, additional packages may be required.
Then Basic Setup (OpenAI + ChromaDB Example)
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'your-openai-key', 'model': 'gpt-4'})
vn.train(schema='your_schema', logs='your_query_logs')
vn.ask("What are the top 5 products by revenue?")
🎓 Training Vanna AI
You can improve Vanna’s output quality by training it on your:
✍️ DDL Statements
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my_table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
📚 Business Documentation
vn.train(documentation="Our business defines XYZ as ...")
📈 SQL Query Examples
vn.train(sql="SELECT name, age FROM my_table WHERE name = 'John Doe'")
💬 Ask Questions
vn.ask("What are the top 10 customers by sales?")
Returns:
SELECT c.c_name AS customer_name,
SUM(l.l_extendedprice * (1 - l.l_discount)) AS total_sales
FROM lineitem l
JOIN orders o ON l.l_orderkey = o.o_orderkey
JOIN customer c ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales DESC
LIMIT 10;
And if connected to a DB, you also get a result table and a Plotly chart.
🧐 RAG vs Fine-Tuning
| RAG Approach | Fine-Tuning |
| Easily replace LLMs | Hardcoded to one model |
| Cheap to run | Expensive to train & use |
| Easily editable knowledge base | Hard to remove outdated training data |
❓ Why Vanna AI?
✅ Accuracy-first: Improves with more training data
🔒 Data secure: SQL execution & training remain local
🥇 Customizable: Choose your own stack (LLM + Vector Store)
🌟 Ready for production: Jupyter for devs, Streamlit or Slack for users
📦 Interfaces You Can Build With
✅ Jupyter notebooks (great for data analysts)
✅ Streamlit apps (dashboard-ready)
✅ Slack bots (team-friendly)
✅ Flask APIs (for integration into internal tools)
✅ Chainlit (chat-style data assistants)
📉 What It Doesn’t Do (Yet)
- ❌ Data modification (INSERT/UPDATE) is not the focus.
- ❌ Not optimized for non-SQL data sources (e.g., NoSQL).
- ❌ The full install can be bulky (~400MB)—but it’s modular.
💬 Final Thoughts
Tools like Vanna AI represent a shift in how we think about querying data. Instead of expecting everyone to learn SQL, Vanna brings the query layer to where the user is—in plain language.
And because it’s open-source and modular, you’re in full control. No vendor lock-ins. No cloud-only limitations. Just powerful, customizable NLP-to-SQL magic.
📚 Learn More & Contribute
Explore the full documentation and source code on the official GitHub repo.
Have a use case in mind? Fork it. Tweak it. Or just start asking questions—and let your data speak.
About the Author
